How #AI can Lead NFL Pass Rushers
https://www.buccaneers.com/news/shaq-barrett-bucs-new-sack-king-17-5-warren-sapp

Above chart depicts deviations (y axis) from a centroid (orange) -most normal point- of the correlation of multiple dimensions (blue) impact on Max VO2 (ML/KG/MINUTE) in this instance …. Ted Hruzd, Data Scientist & ACSM Certified Personal Trainer… March 2020
INTRO
Can Machine Learning (ML) and AI lead to most optimized fitness programs for specific goals such as:
1. Allow best NFL Defense Line (DL) and Edge Rushers play at top speed every defensive down? 4th Qtr sacks may ice victories.
2. Simultaneously lead Running Backs to simultaneously build more power while developing greater speed (ex: 40 yard dash times) ? 1 or 2 long runs per game be become a game changer?
3. Enable any serious athlete pro or not to recover more quickly from training sessions, thus train intensely 1 more day per week? May allow longer golf drives or faster, more accurate tennis servers, 102 MPH fastball in April (up from max 98 MPH in prior year’s playoffs) for a much needed strikeout for a save and how about a Championship?
Machine Learning / AI can improve accuracy of fitness training progress (Return-On-Investment or ROI) & thus speed up reaching fitness goals (Time-2-Market)
We focus on #1 for now – AI for team’s Best DT’s, DE’s, Edge Rushers
SUMMARY
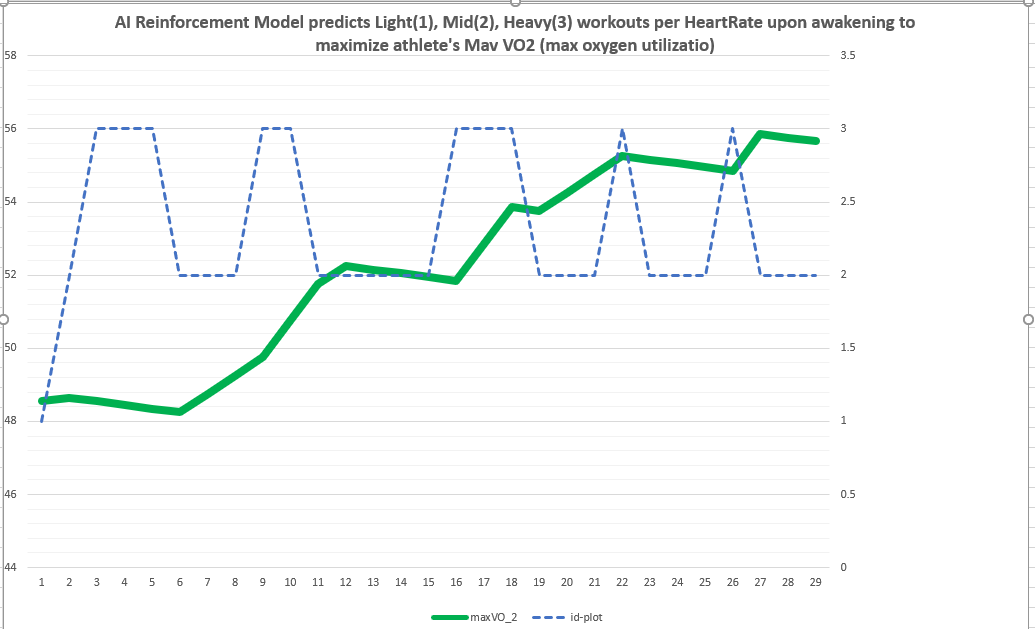
We focus on #1 above. A first step may be to identify multiple factors, which we will refer to as “dimensions” (let’s try about 17). The multi-dimensions in combination at optimal values, can impact positively the lactate threshold of a D Lineman (DL). Results: more 4th Quarter Sacks!
Reference the LACTATE THRESHOLD OPTIMIZATIONS for FOOTBALL DEFENSIVE LINEMEN Section in the 2nd part of the appendix. It provides evidence that Max VO2 (peak aerobic capacity) and Lactate Threshold (LT) are related. Thus, training for Max VO2, at shorter intervals, projects to improve LT. Max VO2 is oxygen utilized per kilogram per minute when at peak aerobic exercise. LT is the level at which blood proteins increase acid in blood stream, limiting muscle cells capacity to fire at peak rates. Try running a sprint at peak speed for longer than 400 yards and chances are you will be forced to slow down significantly unless you are an elite athlete. Proper use of AI can lead even elite athletes to amazing levels! Try running 10 or more 60 yard dashes at top speed with 15 seconds in between. Most will feel fatigued and not be able to keep up top speed. This simulates what college and DL may experience, especially in the 4th quarter and with quick snap counts.
HYPOTHESIS with sample data
Improving LT will enable DL to play all D downs at or near full speed. LT is a limiting factor for continuing repeated downs, some of which can last 5-15 seconds, and exhaust a DL during a drive with quick snap counts. Smart offenses take advantage of this when they see DL sucking air. See below sample raw data I created, essentially to present how the ML model works and how to interpret the results. Imagine if the hypotheses was that:
• running more sprints daily
• speeding up intense exercise recovery via 3 minute sub zero temp nitrogen air baths (equiv of 1 hour ice baths), per R3 Labs – https://www.r3recoverylab.com/
• High % of weight training reps (to max or near max) in range of 8-16 reps
• Increased protein
• Fertilized Egg or Fortetropin (all natural supplement ) produced by https://yolked.com/
Would result in greater improvement in Max VO2 which is correlated with LT
Per my bias in creating sample data, the ML/AI model provides inferences to guide work-outs. Major purposes of this exercise is to
1. prove ML can optimize sports performance
2. encourage DL and Edge Rushers, in this instance, to implement ML/AI with their own data per software I created.
The model identifies anomalies in day-to-day training. The “anomalies” are result of a “Mahalanobis Distance” ML Model. Imagine a 17-dimension ellipsoid with a centroid per all 17 dimensions (factors) all correlated as a group of 17. All accept the outliers may point to improvements in Max VO2. Athletes would be trained to follow training programs as close as possible to the centroid.
Why Machine Learning (ML)
There have been tremendous improvements in accelerated servers and software to speed up inferences from running ML models. The software is near a point where SME’s with just beginners – intermediate programming skills may develop useful ML models.
What is a MAHALANOBIS DISTANCE (MD) VECTOR ML Model
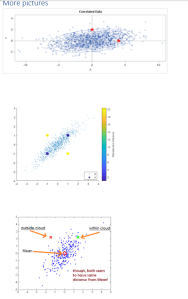
The 2 pictures below depict possible outputs from an MD model. More follow in the appendix.
The first picture plots in blue the deviations of every event (with each event comprised of multiple dimensions) in terms of how far the points deviate from the multi-dimensional centroid. The red line is the threshold. This is actual data from NASA that implemented an MD ML model to define a threshold, then anomalies / alerts prior to outright machine failure. Hence MD ML models can be proactive, even preemptive in their inferences.
The second picture depicts multiple factors (dimensions) via different colors. It is important to realize that all individual dimensions are “normalized” (ex: to account for individual standard deviations). Oval outside the ellipsoid define threshold for anomalies.
Links below will further detail the math behind MD ML. The key points are that in MD ML:
1. All factors are dimensions
2. MD Math calculates multi-dimensions’ correlations for each event. Events may be a day or a second but with data for all dimensions (day in chart below). The multi-dimensional correlations result in deviations form the most common or normal event – the centroid of multiple dimensions.
Next 2 pages: pictures

References:
https://towardsdatascience.com/search?q=machine-learning-for-anomaly
Mahalanobis Distance – Understanding the math with examples (python)
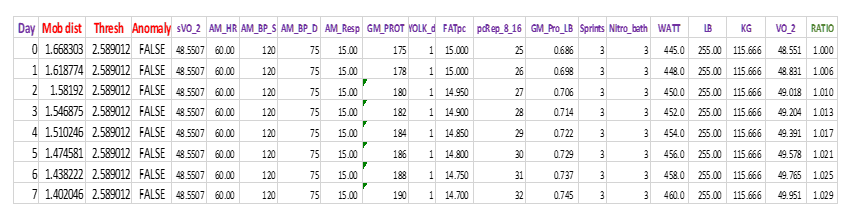
RAW DATA
For NFL MD ML
snippet

Description of all Dimensions (Inputs)
• Day – for MD ML I will dive deep in is the Event – ex Day 0 1st day of training
• Mob dist, Thresh, Anomaly attained after MD ML runs and provides the Threshold ceiling for all events, with Anomaly column rating whether event is Anomaly or not
The above are derived, not Dimensions.
Dimensions start with:
• sVO_2 – starting Max VO2, will be same for all events
• AM_HR – heart rate upon awakening … rule or guide whether to train or not or how heavy
• AM_BP_S- Systolic BP upon awakening … rule or guide whether to train or not or how heavy,
• AM_BP_D- Diastolic BP upon awakening … rule or guide whether to train or not or how heavy,
• AM_Resp – breaths per minute upon awakening … guide whether to train or not or how heavy
• GM_PROT – grams protein
• YOLK_d – servings of fortetropin
• FATpc – Body Fat % at least within past 7 days
• pcRep_8_16 – % of strength training sets that were in rage of 8-16 reps for sets carried to failure or near, may have correlation with MaxVO2
• GM_Pro_LB – ratio of grams of protein to pounds
• # Sprints that last between 30-60 seconds at near all out speed – evidence to support positive impact on both lactate threshold (LT) and Max VO2
• Nitro_bath – minutes in sub zero Nitrogn tank for muscle and cardio recovery
• WATT – Power / energy expended in cycling – peak 30 second rate. This is used in a formula that results in predicting Max VO2
• LB & KG– players weight in pounds & KG. KG is used in formula for Max VO2
• VO2 – Column lists calculated MAX VO2 – ML O2 per KG / MINUTE
• RATIO – ratio of current Max VO2 vs starting (sVO_2). See event 7 1.029 means it increased by 2.9%. This is the GOAL – increase Max VO2 which is correlated with increases in Lactate Threshold (LT).
Next page details how to interpret MD ML results.
FORENSICS
The MD ML will point to just prior events that lead to Anomalies.
Threshold was exceeded

Forensics just before the anomalies point to combined effect of multiple dimensions that together contributed to increases in Max VO2 – rows with green; then same dimensions Day 37 changed significantly, ranging from
• increased morning heart rate (flag for over training)
• increased BP
• increased respiration rate (flag for over training)
• decreases in protein & Yolked (fortetropin); both which tend to work together to maintain, increase muscle mass & strength
• decrease in # sets with 8-16 reps per set as part of strength training .. this rep range 8-16 (for at or near max) may be most optimum for LT
• decrease in 30-60 second sprints; repeated 30-60 second sprints are a core recommendation for increasing Max VO2 & LT … 10 may be optimum although it can vary person-person; timing of the sprints should be considered. Most training programs advocate near end of work-out
• decrease in time spent in R3Labs nitro sub zero booth: R3 nitro booths speed up recovery post r intense workouts
Next – View where Threshold came close to being exceeded
I leave it up to the reader to rate the below forensics and provide the inference insights.
It is interesting to note though, that the threshold was close to being exceeded while the success criteria was degrading. One thus may need to lower the threshold for anomalies; or one may need to run exercise training sessions very close to low deviations from the multi-dimensional centroid.

How to Tweak ML further
One can decrease the dimensions to determine which together are most relevant together. Another ML “autoencoder neural network” can be run on the same data that will accomplish this.
ML often is an iterative process.
Also one can run multiple ML models but with different hyper partners which may lead to more accurate projections – all on the same data, concurrently in Docker containers in GPU’s or other accelerated compute platforms. So I digress into deep Tech …. & return now return back to practical recommendations how to proceed with this.
CONCLUSIONS & NEXT STEPS
The example showcased here depicts what is possible with ML/AI for Fitness. One can attain very useful inferences for the MD ML presented here. This may be enhanced by adding additional dimensions such as nutrition related:
• Mg Coenzyme Q
• Tart Cherry Juice
• Nitric Oxide Precursors
Or Practice Field related
• # reps on blocking sled
• # minutes agility drills
• # simulated pass rushing drills like 15 second downs with 15 seconds in between the drills, simulating quick snap counts
Anomaly Engines can be combined with Reinforcement Learning (RL) ML’s. RL learns over time what are most successful actions to reach clear goals. The 1st 2 RL links pertain to my main world – Electronic Trading, to attain best prices and thus revenue in trading securities. The next 3 links are more generic.
A specific RL model can be developed and run so it continuously learn of optimal exercise training programs for our task here improve LT / Max VO2 so the best DL linemen and Edge Rushers can play every Defensive down at top speed / energy, come up with 4th Qtr sacks to secure wins. Combining that with Anomaly Engine will further increase accuracy.
https://towardsdatascience.com/aifortrading-2edd6fac689d
View at Medium.com
https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292
https://towardsdatascience.com/deep-reinforcement-learning-tutorial-with-open-ai-gym-c0de4471f368
https://towardsdatascience.com/reinforcement-learning-from-scratch-designing-and-solving-a-task-all-within-a-python-notebook-48c40021da4
AI FIT LLC (soon to be) Consulting
About the Author
Ted Hruzd combines his passion as a personal fitness trainer with technical leadership in Artificial Intelligence and Machine Learning. That enabled him to create an individualized training program that maximizes an athlete’s performance when it counts the most “In the Game”! Together it improves accuracy of fitness training progress and speeds up reaching fitness goals.
Ted delivers innovative AI and ML solutions in high speed trading on Wall Street and teaches his craft as a lecturer at NYU and previously at Rutgers, where he also provided ML/AI for Pharma and Fitness industries. He is also an #ACSM personal fitness trainer with over 12 years of experience.
If interested, or require more details, discuss this further per a Zoom Session with Ted: tedhruzd@gmail.com or 1-917-318-2318
Ted
Appendix follows
Appendix
More pictures
AI-FIT
https://www.google.com/amp/s/www.standard.co.uk/tech/ai-fitness-app-perfect-squat-challenge-app-a3871881.html%3famp
Above KAIA is the company
Partner?
https://kaia-perfect-squats.app.link/challenge
LACTATE THRESHOLD OPTIMIZATIONS for FOOTBALL DEFENSIVE LINEMEN
Lactate Threshold (LT) & VO2 Max do correlate
https://hvmn.com/blog/training/vo2-max-training-to-use-oxygen-efficiently
anaerobic respiration: The only fuel that can be burned anaerobically is carbohydrate, being converted into a substance called pyruvate through glycolysis and then into lactate via anaerobic metabolism.
On verge of Lactate Threshold (LT), the blood becomes more acidic, which in turn can compromise muscle function.
LT is expressed in milliliters of oxygen per minute per kilogram of bodyweight–this is the relative number most often considered a VO2 max.
Optimal way to test is in lab tests. A facemask is placed on subjects to measure the volume and gas concentrations of inhaled and exhaled air. Similar to lactate testing in a sports lab, athletes run on a treadmill (or sometimes use a stationary bike or rowing machine, depending on sport) and the exercise intensity increases every few minutes until exhaustion (read: you start having tunnel vision, hit the red stop button and collapse into a sweaty heap). The test is designed this way to achieve maximal exercise effort from the subject.
Training will be geared toward improving this point, at which the body begins to accumulate lactate in the blood.
Similar tests can be replicated outside of labs with less accuracy.
Your maximum heart rate: This formula might oversimplify things, but it’s effective for the purposes of a loose VO2 max calculation. To find your max heart rate, subtract your age from 220. So, if you’re 30 years old, your maximum heart rate is 190 beats per minute (bpm).
Use this formula to find your simple VO2 max: 15 x (max heart rate / resting heart rate).
Rockport Fitness Walking Test (RFWT)
This walking test can also calculate a VO2 max, and studies have proven its accuracy.
First, stretch and warm up. Then, find a track or mostly flat surface on which to walk a mile as fast as possible. It’s important to walk, and not to cross over into jogging territory. After walking exactly one mile, note exactly how long it took and your heart rate at the end of the mile. Using those numbers, you’ll be able to find an estimated VO2 max using this formula:
Walk
VO2 max = 132.853 – (0.0769 x W) – (0.3877 x A) + (6.315 x G) – (3.2649 x T) – (0.1565 x H)
W = weight (in pounds)
A = age
G = gender (1 for men, 0 for women)
T = time to complete the mile (in minutes)
H heart rate
Bike
O2 max = [(10.8 x W) / K] + 7
W = average wattage
K = weight in kilograms
Training is designed to have you spend as much time as possible at 95% – 100% of your current VO2 max as possible.
Because lactate threshold and VO2 max are linked, Interval training often results in the most improvement of VO2 max.
1000 meters
you are good at pacing yourself, sessions made up of long (4 minutes or so) intervals at your hardest sustainable effort are a good way to increase VO2 max. Between each interval, you should keep moving; active recovery will keep VO2 elevated during the process. Plan to do 4-6 sets.
Save enough energy so that your last set is the hardest intensity.
Athletes who did a similar workout improved their VO2 maxes by 10%. Time to exhaustion, blood volume, vein and artery function all improved after the training period.
Short interval sprints of under one minute can also improve VO2 max as long as they’re conducted at almost maximal effort level.
Exercise test here is 8-10 sets of 1 minute sprints. Again, make sure you are properly warmed up–these workouts carry a risk of injury because of the amount of power produced. You have to give it your all during each interval without holding anything back.
From the same study mentioned above, those doing ten sets of one-minute high-intensity sprints on a treadmill at maximum rate (with a 1 minute rest in between each interval) increased VO2 max by 3%.
Time to exhaustion, plasma volume and hemoglobin mass increased with this routine. However, results demonstrated that long interval training garnered the most dramatic results.
https://hvmn.com/blog/training/lactate-threshold-is-misunderstood#optimizing-lactate-metabolism
For many, the goal of training is to maintain increased power and speed without crossing over this threshold. Most athletes want to stave off blood lactate accumulation, training so they clear it faster and produce less.
Nutrition a key
Glucose gets metabolized by a process called glycolysis, resulting in pyruvate. There are two possible uses for pyruvate: anaerobic or aerobic energy production. Lactate caries a proton (an acid) when it’s released, and the build up of protons decreases the pH of the blood. When the body gets more acidic, function becomes compromised because the protons interfere with energy production and muscle contraction. But upon arriving at the lactate threshold, the blood concentration of lactate begins to exponentially increase. Usually that intensity hovers around 80% of an athlete’s maximum heart rate, or 75% of their maximum oxygen intake–but you can also link it to speed or power.
Well-designed training programs target both sides of the lactate threshold; there should be some training sessions working at or above LT. These sessions are harder on the body, but this forces adaptations that ultimately increase speed on race day.
ATP is produced from carbs through a three-step process: Glycolysis, Krebs Cycle and Electron Transport Chain (ETC). Products from Glycolysis feed Krebs which feeds ETC.
Protocols to determine lactate threshold are sport-specific. Many consider the running speed at lactate threshold (RSLT) to be the best indicator of running fitness and the most reliable barometer of endurance performance.
Cycling, step-tests (where power is increased at regular intervals until you are exhausted) are the gold standard for measuring physiological performance markers, such as lactate threshold.
Concrete way to determine lactate threshold is to take a series of blood samples as exercise is conducted at increasing intensities. This type of lactate testing occurs at an exercise physiology laboratory, and tends to be expensive (but worth it).
Lactate threshold test, athletes exercise on a treadmill or stationary bike while increasing intensity every few minutes until exhaustion. A blood sample is taken during the each stage of the test–similar to testing for ketones, through the fingertip or earlobe–illustrating blood lactate readings at various running speeds or cycling power outputs. Results are then plotted on a curve to show the speed or power at which the lactate threshold occurs.
Lactate threshold changes as more training is done to build your aerobic base. So in order to maintain an updated understanding of your lactate threshold, you’d have to visit the lab again after a block of trainin
endurance athletes choose to estimate their lactate threshold by measuring heart rate and/or VO2 max at different training zones (there’s even a portable lactate blood analyzer some use to further cement results).
Note correlation
VDOT (or VO2 max) Chart
example, running at a 7:49 mile pace at max effort corresponds to a VDOT number of 36. That VDOT number illustrates the pace at which training should be done to maintain lactate recycling: 8:55. For a more in-depth analysis of interval training and different distances, refer to these charts here
heart rate against speed; the deflection point in the graph (where your heart rate goes up much more than your speed) roughly corresponds to speed at lactate threshold
heart rate at the 10-minute mark to heart rate at the 30-minute mark–that’s your lactate threshold heart rate. And your average pace for the entire 30-minute test (assuming it was steady) is your lactate threshold pace
However, lactate threshold is impacted by training and changes over time. So keeping regular on these types of tests will indicate an improving lactate threshold through focused training.
Warming up is important to reducing risk for injury and minimizing potential lactate buildup. During a warm-up, heart rate increases, and blood vessels dilate, meaning there is more blood flow and more oxygen reaching your muscles.
Equally, cooling down and stretching immediately after a workout is especially important. Gentle exercise (slow jogging or spinning on a bike) or using a foam roller can help clear lactic acid buildup from the muscle by stimulating blood flow and encouraging lymphatic drainage.
key to dealing with high lactate production is dealing with the acid associated with it (that pesky little proton). Two “buffer supplements,” sodium bicarbonate and beta-alanine, work by mopping up that proton. This means lactate levels can go higher than before without triggering fatigue because the proton is taken care of.
Beta-alanine works inside the muscles to clean up protons before they affect muscle contraction. Compounding effects of beta-alanine powder (~5g per day) happen after several weeks, but studies show around a 2-3% performance boost.4
Bicarbonate is the main buffer usually binding protons to stop blood from becoming too acidic. About an hour before exercise, taking bicarb powder dissolved in water, at 0.3kg per body weight, has shown to improve performance.5 Be weary of stomach aches when first introducing bicarb. But there are bicarbonate gels that provide the same buffing effect without the side-effects.6
Exogenous ketones can lower lactate production. By drinking pre-workout exogenous ketones, like HVMN Ketone, your body can use the ketones for energy instead of carbohydrates–glycolysis decreases and therefore, so does lactate production.
the whole body, the heart muscle gets stronger, building more small blood vessels. These small blood vessels mean more oxygen-rich blood can be transported to the muscles, requiring less demand for anaerobic respiration and lactate production.
On a muscular level, cells can produce more mitochondria, which are the site of aerobic respiration. This helps increase reliance on that energy system. Muscle cells also express more of the transport proteins for lactate, so lactate doesn’t build up inside the cells and compromise their function.8
runners, one way to work on lactate threshold is to breakdown a run into mile sections: the first mile or two should be run at a pace just below lactate threshold, while the proceeding mile section should be slower, thus allowing the body to process the lactate. Active recovery is more effective at clearing lactate than passive recovery.9 This allows a high volume of miles without going overboard.
altering how the body responds to lactate with nutrition supplements like HVMN Ketone and bicarb gels. And in the process, we’re rewriting the old story about lactic acid.
VO2 max: The Apple Watch metric that reveals your aerobic fitness
If you want to know how you compare to typical VO2 max levels, check out this chart.

https://hvmn.com/blog/training/vo2-max-training-to-use-oxygen-efficiently
https://hvmn.com/blog/training/lactate-threshold-is-misunderstood#optimizing-lactate-metabolism